지도학습 머신러닝을 통해 해결하는 두 가지 문제는 회귀(Regression)와 분류(Classification)이다. 전통적인 머신러닝 모델들인 선형회귀(Linear Regression), 서포트벡터머신(SVM: Support Vector Machine)을 Python 코드로 회귀와 분류 모델에 대해 알아보자.
본 포스트의 목적은 회귀와 분류에 대한 대략적 개념을 소개하는 것이므로, 세부적인 수학적 원리는 생략한다. 수학적 원리와 더 자세한 머신러닝 원리를 알기 원하는 사람은 관련 자료 및 유튜버 3Blue1Brown의 Neural Networks Series을 참고하면 좋다.
선형회귀
회귀분석이란 독립변수들(feature)과 목적변수 혹은 종속변수(target) 사이의 관계를 구체적으로(일반적으로는 회귀방정식이라는 수식을 통해) 분석하는 방법론이다. 선형회귀는 회귀 분석의 일종이다. 선형회귀는 회귀방정식을 선형 형식(linear form, 선형 형식의 n차원 일반화)으로 취한다.
선형회귀의 목적은 오차를 최소화시키는 파라미터를 구하는 것이다. 이렇게 오차를 최소화시키는 방법을 수학적 최적화라고 한다. 이러한 최적화 방법은 매우 다양하고, 본 포스트에서 다루는 회귀와 분류 뿐만 아니라 비지도학습, 강화학습까지 널리 사용되고 현재도 연구되고 있는 분야이다. 기본적으로 선형회귀의 최적화 방식으로는 최소제곱법과 경사하강법등이 사용된다.
선형회귀의 오차는 일반적으로 '실제 데이터'와 '예측된 데이터'의 차이의 제곱의 합으로 표현한다. 이때 '실제 데이터'와 '예측된 데이터'의 차이의 제곱을 제곱오차라고 한다. 오차의 정의가 선형회귀의 오차를 실제 데이터와 예측 데이터의 차이이므로 이 둘의 차이를 이용한다는 것은 쉽게 수긍할 수 있다. 그런데 왜 차이에 제곱을 하는 것일까? 이는 우리가 통계에서 분산을 구할 때 제곱을 하는 이유와 같다. '차이'는 큰 수에서 작은 수를 빼는 것이고 이는 두 수의 부호에 관계없이 양수값이다. 하지만 우리가 차이를 구할 때 사용하는 뺄셈은 다르다. 뺄셈 연산에서 전항이 후항보다 클 필요는 없다. 전항이 후항보다 작아도 뺄셈 연산은 잘 정의된다(Well-defined)는 것이다. 따라서 뺄셈의 값은 양수, 음수 모두 가능하다.
따라서 전체 오차를 각 실제 데이터와 예측 데이터의 차이로 정의하고 $\sum (실제 데이터) - (예측 데이터)$으로 정의하면 더하는 과정에서 양수와 음수가 모두 더해지고, 전체 오차의 실제 크기와는 관계없는 값이 산출될 것이다. 이런 상황을 피하기 위해 오차를 산출할 때 제곱을 하여 부호에 관계없이 양수로 만드는 것이다. 이와같이 정의하면 오차의 크기가 증가하면 전체 오차값도 증가하는, 적절한 형태가 된다.
그렇다면 한번
| $x$ | $y$ |
|---|---|
| 1 | 3 |
| 1.3 | 3.1 |
| 1.7 | 3.4 |
| 2.0 | 4.5 |
| 2.25 | 4.0 |
| 2.4 | 4.1 |
| 2.5 | 3.85 |
| 2.7 | 5.5 |
| 3.0 | 6.25 |
| 3.1 | 7.05 |
| 3.5 | 7.0 |
이를 다음과 같이 산포도로 시각화할 수 있다.

이 데이터를 경사하강법을 이용한 선형회귀로 분석해보자.
data_lt = ... # data_lt에는 주어진 데이터를 n X 2 형태로 표현함.
delta_x = 0.0001
step_size = 0.001
init_coefficient = 3
init_constance = 1
repeat = 10000
def diff_cal(func, val):
return (func(val + delta_x) - func(val)) / delta_x
def del_op(func, val_x, val_y):
return (diff_cal(lambda x: func(x, val_y), val_x),
diff_cal(lambda y: func(val_x, y), val_y)
)
def error_func(coefficient, constance):
error = 0
for x, y in data_lt:
error += (y - (coefficient * x + constance)) ** 2
return error
coefficient = init_coefficient
constance = init_constance
for _ in range(repeat):
(delta_coefficient, delta_constance) = del_op(error_func, coefficient, constance)
delta_coefficient *= -step_size
delta_constance *= -step_size
coefficient += delta_coefficient
constance += delta_constance
그 결과를 시각화 하면 다음과 같다. 최적화 전 초기의 방정식은 파란색 실선이고, 최적화 후의 방정식은 빨간색 실선이다.

선형회귀분석은 이와같이 데이터가 선형적인 양상을 보일 때 주로 사용된다.
서포트벡터머신
선형회귀는 그 자체로 훌륭한 통계기법이지만 회귀 문제에만 사용할 수 있고 분류 문제에는 사용할 수 없다. 반면 서포트벡터머신(SVM)은 회귀, 분류 문제 모두에 사용할 수 있고, 커널(kernel, 주의: OS의 커널과는 다름)을 자유롭게 선택할 수 있는 장점이 있다. 커널, 또는 핵이란 회귀, 분류 문제에서 데이터 처리의 기준이 되는 수식을 의미한다. 가령 선형회귀에서의 커널은 선형 형식이다. 반면 서포트벡터머신은 선형 형식 뿐만 아니라 n차 다항식, 원의 방정식 등 다양한 검증된 커널이 존재한다.
다양한 커널을 사용할 수 있다는 것은 다양한 데이터 분포를 쉽게 분석할 수 있다는 뜻이다. 가령 다음과 같은 데이터는 선형회귀로 분석하는 것이 불가능하다.
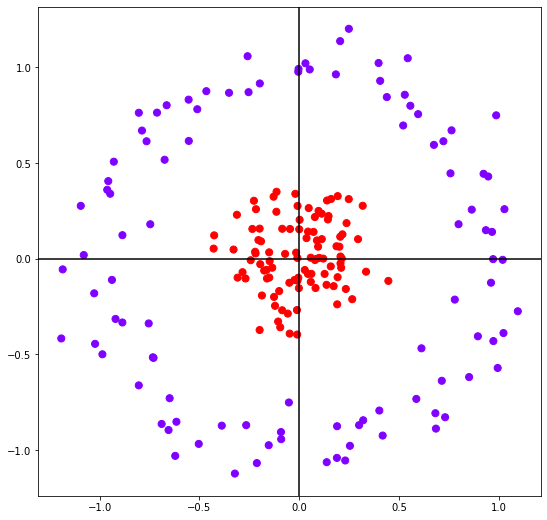
이를 선형회귀로 분석하기 위해서는 다음과 같이 커널 트릭(kernel trick)을 사용해야 한다.
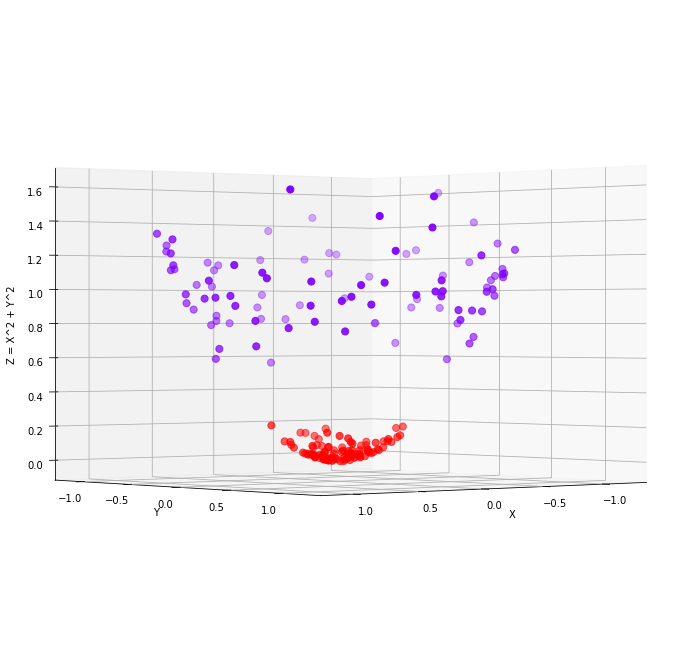
이와 같은 커널트릭을 사용하면 3차원의 선형인 평면의 방정식을 통해 분류 문제를 해결할 수 있다. 하지만 커널 트릭의 난이도는 높은 편이므로, 서포트벡터머신을 통해 분석하는 것이 더 수월하다. 서포트벡터머신의 수학적 구현은 선형회귀와 달리 간략하지 않다. 하지만 scikit-learn 라이브러리를 활용하면 쉽게 구현할 수 있다.
from sklearn.linear_model import SVR
'''
데이터 초기화 코드
'''
svr_model = SVR().fit(X_train, y_train)
y_pred = svr_model.predict(X_test)
서포트 벡터 머신의 원리는 마진(Margin) 을 최대화하는 데에 있다. 전체 데이터 집합 중 모델과 가장 가까운 데이터와 모델 사이의 거리를 마진이라고 한다. 이 마진을 최대화하는 방향으로 모델을 수정해나가면 가장 좋은 모델을 얻을 수 있음이 증명되었다. 서포트 벡터 머신은 이를 이용하여 마진을 증가시키는 방향으로 모델을 개선하고 딥러닝이 대두되기 전까지 일반적으로 가장 좋은 성능을 가지는 통계적 모델이었다.
다음 포스트에서는 로지스틱 회귀(Logistic Regression), 의사결정트리(Decision Tree)를 다룰 것이다.
출처: AWS 클라우드 머신러닝(아비섹 미쉬라, 박정현 옮김), 에이콘, 2021