참여 인원
- 박수빈: 총괄, 크롤러 개발, 데이터 전처리, AI 모델 설계 및 구현
- 박현진: 크롤러 개발, DB 구축 및 관리, 크롤링 수행, 데이터 전처리
- 이승윤: AI 모델 하이퍼파라미터 튜닝 및 세부 설계 및 구현, 모델 학습
- 이동욱: 금융 데이터 수집 및 탐색, 데이터 라벨링 자동화 구축
개요
유발 하라리의 '사피엔스'에 의하면 인간은 물리적 세계뿐 아니라 상호주관적 세계에서 살아간다. 국가, 법, 기업, 돈과 같은 추상적 개념은 실제로 존재하는 개념이 아니라 허구적 개념이다. 하지만 많은 사람들이 이러한 허구적 개념을 마치 실존하는 것처럼 인식하고 행동하기 때문에 실존하는 것처럼 현실 세계에 영향을 미친다. 이러한 상호주관적 개념은 정량적으로 분석하기 어려운 분야였다. 상호주관적 개념들을 수치화하여 정량적으로 분석하고자 하는 시도는 오래전부터 존재했지만, 자료(데이터) 접근에 대한 제한과 이를 처리할 기술의 부족은 난점으로 남아있었다. 하지만 오늘날의 상당한 행위가 전자적으로 이루어짐에 따라 개개인의 움직임은 데이터로 쉽게 전환되었고, 정보의 이동 속도는 물류의 이동 속도를 추월하게 되었다. 또한 오늘날 빅데이터 처리 기술은 매우 방대한 양의 데이터를 수집하고 저장하는 것을 가능하게 했고, 딥러닝 혁명은 거대한 데이터를 바탕으로 새로운 통찰과 결정을 도출하는 것을 가능하게 했다.
데이터로 상호주관적 세계를 분석할 수 있다면 인간의 주관에 큰 영향을 받는 다양한 영역을 새로운 시각에서 예측하는 것도 가능할 것이다. 이에 대한 대표적인 예는 금융 영역이 있다. 일반적으로 금융시장은 효율적 시장가설을 따른다고 받아들여졌다. 투자자들은 모든 정보를 분석하여 자신의 투자를 결정하고, 이에 따라 모든 금융상품은 자신의 공정한 가격을 찾는다. 그러나 금융시장을 움직이는 것은 물리학적 힘이 아닌 인간의 의지이기에, 효율적 시장가설은 단기적으로는 성립하지 않는다. 비이성적 과열, 야성적 충동, 내러티브 경제학 등의 용어는 그러한 금융시장의 불확실한 변동성을 보여준다. 하지만 텍스트 데이터와 같은 더욱 '인간적인' 데이터를 기반으로 다각적으로 접근한다면 변동성을 조금 더 정확하게 분석하고 예측할 수 있을 것이다. 이는 금융시장이 결국 인간의 활동으로 환원된다는 점에서 자연스럽다.
이를 위하여 현재까지 접근한 방식은 인공지능, 그 중에서도 딥러닝을 통한 자연어 처리(Natural Language Processing)이다. 자연어 처리는 컴퓨터가 인간의 언어를 이해, 생성, 조작할 수 있도록 해주는 인공지능의 한 영역이다. 인간이 의지를 보통 표현하는 방식이 언어인 만큼, 언어 데이터는 곧 인간 행위의 많은 모습을 설명해 준다.
결론적으로 최종적인 목표는 기존의 금융공학에서 사용되었던 수치적인 접근에 더하여, 기계학습을 통해 비정형 데이터까지 처리한 상품성 있는 예측 서비스를 구축하여 공급하는 것이다. 이러한 모델 공급을 통해 금융상품의 적절한 가격 도출에 일조하여 금융시장의 건전성을 도모한다는 사회적 책임또한 다할 것이다.
크롤링
데이터 도메인
텍스트 데이터 도메인은 각 신문사 뉴스 기사, 트위터, 네이버 종목 토론방으로 설정했다. 각 신문사 뉴스 기사에서는 각 주식 종목에 대한 명시적이고 주식 가격에 명시적으로 영향을 미치는 주식 가격 데이터를, 트위터, 네이버 종목 토론방은 기업 주식 가격에 대한 암시적인 결정 요인을 파악하는 데 사용했다. 이는 명시적이고 출처가 명확한 정보 뿐만 아니라 여러 소문과 해당 금융상품에 대한 암시적인 분위기 또한 주식 가격에 영향을 미치는 것으로 판단한 결과이다.
크롤러 개발
텍스트 데이터 크롤러에 대한 오픈소스 공개 버전인 FinTextCrawler는 해당 링크에서 확인할 수 있다.
텍스트 데이터 크롤러는 requests, selenium, beautifulsoup4, w3lib 기반으로 자체 개발되었다. requests는 Open API 및 타 API로 JSON, XML 형식의 데이터를 얻을 때 사용되었고, selenium은 동적 요소가 있는 일반 웹 페이지를 크롤링할 때 적용되었다. 신문기사 크롤러는 Naver API의 뉴스 검색 기능을 이용해 뉴스 기사들의 링크들을 받고 얻은 링크들을 순차적으로 방문하는 방식으로 크롤러를 설계했다. 트위터의 경우 트위터의 API를 통해 각 키워드에 따른 트윗 데이터를 받고 해당 링크를 BFS로 탐색하는 방식으로 크롤링을 진행했다. 네이버 종목 토론방의 경우, 인덱스 페이지 상의 URL을 순차적으로 방문한 후에 다음 인덱스 페이지를 방문하는 방식을 재귀적으로 반복하여 크롤링했다.
수집한 데이터 중 Open API는 파이썬 표준 라이브러리인 json을 이용해 파싱했다. 웹 페이지는 beautifulsoup4, w3lib을 통해 파싱했다. 다음은 텍스트 데이터 파싱 코드의 일부이다.
article_body = str(soup.find('div', id='dic_area', class_='go_trans _article_content').extract())
article_body = re.sub(r'<div class="go_trans _article_content".*?>', '', article_body)
'''
일부 생략
'''
article_body = remove_tags(article_body)
article_body = re.sub('\n{2,}', '', article_body)
article_body = article_body.replace('△', '').replace(u'\xa0', u' ')
article['article'] = article_body
해당 코드는 기사 본문을 파싱하는 코드의 일부이다. 이처럼수집한 웹 페이지의 HTML 파일 중 유의미한 정보를 담고 있는 부분을 인식하고 저장하도록 크롤러를 개발했다.
금융상품 가격 데이터는 investing.com에서 수집했다. 초기에는 kaggle등에서 공개된 데이터를 얻고자 했으나 시간별 주식 데이터는 구하기 쉽지 않았고 유일하게 찾은 제공처는 유료로 제공했기 때문에 직접 데이터를 크롤링하기로 결정했다. 금융 데이터의 크롤링은 텍스트 데이터와는 별도로 진행되었기 때문에 데이터를 csv 파일에 캐싱한 후 주기적으로 데이터베이스에 전송하면서 진행되었다. investing.com의 웹 페이지 구조는 크롤링을 막기 위해 의도적으로 난해하게 설계되었기 때문에 크롤링은 온전히 자동화된 크롤링이 아닌 부분적으로 자동화된 방식으로 진행되었다.
최종적으로 모든 텍스트 데이터와 금융상품 가격 데이터는 데이터베이스(이하 DB)로 전송하여 저장되었다.
크롤링 환경 및 과정
-
운영체제 및 기타 환경 크롤링은 자체 서버를 활용했다. 개발 초기 AWS 상의 서버를 활용하는 것도 고려했으나 대역폭에 제한이 있고 원하는 성능 수준을 얻기 위해서는 추가 비용을 지불해야 했기 때문에 자체 서버를 사용하고 SSH등의 원격 제어 프로토콜로 제어하는 방식으로 크롤링을 진행했다. 운영체제는 Ubuntu-Linux로, 팀원들 모두 Linux에 익숙하고 사용 소프트웨어들과 호환성이 좋으며, 관련 자료를 구하기 쉽기 때문에 선택했다.
-
데이터베이스 DB는
MySQL로 선정했다. 오픈소스 기반으로 널리 사용되고 쉬운 설치 및 구성이 가능하여 선정했다. 파이썬의MySQLdb패키지를 통해MySQLDB와 연결하여 데이터의 처리와 저장 과정을 자동화 하였다.
DB의 필드는 다음과 같다.
- 신문사 기사 DB 필드
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| article_No | int(7) unsigned zerofill | YES | NULL | ||
| article_id | int | NO | NULL | ||
| press_id | int | NO | NULL | ||
| title | text | NO | NULL | ||
| author | text | NO | NULL | ||
| published_datetime | datetime | NO | NULL | ||
| article | text | NO | NULL | ||
| useful | int(5) unsigned zerofill | YES | NULL | ||
| wow | int(5) unsigned zerofill | YES | NULL | ||
| touched | int(5) unsigned zerofill | YES | NULL | ||
| analytical | int(5) unsigned zerofill | YES | NULL | ||
| recommend | int(5) unsigned zerofill | YES | NULL |
- 트위터 데이터 DB 필드
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| tweet_No | int(7) unsigned zerofill | YES | NULL | ||
| posted_datetime | datetime | NO | NULL | ||
| tweet_id | int | NO | NULL | ||
| tweet | text | NO | NULL |
- 네이버 종목 토론방 DB 필드
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| article_no | int(7) unsigned zerofill | YES | NULL | ||
| title | text | YES | NULL | ||
| published_datetime | datetime | YES | NULL | ||
| body | text | YES | NULL | ||
| view | int | YES | NULL | ||
| good | int(4) unsigned zerofill | YES | NULL | ||
| bad | int(4) unsigned zerofill | YES | NULL |
데이터 수집을 진행한 타겟 시기는 10월 중순에서 현재까지의 카카오와 SPC로 결정했다. 큰 문제가 발생했을 당시 텍스트 데이터가 어떤 양상을 가지는지, 그리고 대략 3개월 정도가 경과한 현재까지의 흐름이 어떠한지 파악함으로써 관계를 면밀히 탐구할 수 있을 것이라 기대했다.
데이터 전처리
데이터 탐색과 전처리에 대한 코드는 해당 링크에서 확인할 수 있다. 전처리에 대한 코드는
Preprocessing폴더에서 확인할 수 있다.
데이터 탐색
프로젝트 목표를 위해 사용한 데이터는 텍스트 데이터와 주가 데이터이다. 주가 데이터는 시가/저가/고가/종가를 포함한다. 본 프로젝트에서 사용한 가정은 폐장 이후 개장 전까지의 투자 움직임은 익일 정오까지 반영된다는 것이다. 또한 금요일 폐장 이후 월요일 개장 전까지의 투자 움직임은 월요일 정오까지 반영됨을 전제하였다. 따라서 이를 바탕으로 텍스트 데이터와 주가 데이터를 전처리 후 비닝하였다.
또한 데이터 탐색 과정에서 뉴스 기사 데이터의 시계열 상 분포가 불균일하고 특정 시기에 몰려있음을 확인했다. 이는 모델의 성능에 악영향을 미칠 수 있으므로 현재 개발된 초기 모델의 구현에서는 뉴스 기사 데이터 학습을 제거하고, 데이터를 추가로 수집한 후 모델 학습에 적용하기로 결정했다.
데이터 전처리
텍스트 데이터 전처리는 URL등 자연어 처리 모델이 분석하기 어려운, 의미를 찾기 어려운 데이터들을 제거하고 데이터 중 자연어 처리 모델에 유의미한 데이터를 골라 Aggregation을 수행하는 방식으로 진행했다.
자연어 데이터 중 불필요한 데이터는 다음과 같이 처리했다.
url_re = '(?:www\.)?[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}\b(?:[-a-zA-Z0-9()@:%_\+.~#?&\/=]*)'
df_community['article'] = df_community['article'].str.replace(url_re, '')
df_community['article'] = df_community['article'].str.replace('^n', '')
df_community['article'] = df_community['article'].str.replace('n(?![a-zA-Z ])', '')
df_community['article'] = df_community['article'].str.strip()
데이터 Aggregation은 다음과 같은 인덱싱을 통해 수행했다.
bins = [0, 7.5, 12, 15, 24]
labels = ['_Closed', '_AM', '_PM', '_Closed']
period = pd.cut(df_community['Date'].dt.hour, bins=bins, labels=labels, include_lowest=True, ordered=False)
period[df_community['Date'].dt.day_of_week > 4] = '_Closed'
date = df_community['Date'].dt.date.astype(str)
df_community['DayIndex'] = date.str.cat(period)
df_community = df_community.drop('Date', axis=1)
금융상품 가격 데이터의 경우 모델에 데이터를 대입했을 때 모델의 성능하락을 막고자 MinMax Scaling을 다음과 같이 적용했다. 시계열 데이터이므로, 흔히 쓰이는 다른 방식인 Standard Scaling 대신 MinMax Scaling을 적용하여 전처리했다. 전체 시가, 종가, 고가, 저가의 전체 데이터셋을 평가변환을 통해 하나의 벡터로 변환한 후 MinMaxScaler에 대입해 Scaling 계수를 설정했다. 마지막으로 설정된 MinMaxScaler에 가격 데이터를 대입하여 MinMax Scaling을 수행했다.
eval_vector = new_df'Open', 'High', 'Low', 'Close' Private or Broken Links
The page you're looking for is either not available or private!
.to_numpy().reshape(-1, 1)
scaler = MinMaxScaler().fit(eval_vector)
new_df['Open'] = scaler.transform(new_df['Open'].to_numpy().reshape(-1, 1))
new_df['High'] = scaler.transform(new_df['High'].to_numpy().reshape(-1, 1))
new_df['Low'] = scaler.transform(new_df['Low'].to_numpy().reshape(-1, 1))
new_df['Close'] = scaler.transform(new_df['Close'].to_numpy().reshape(-1, 1))
최종적으로 금융상품 가격 데이터와 텍스트 데이터에 다음 코드를 적용하여 하나로 묶었다.
total_df = stock_df.set_index('DayIndex')
total_df['CommunityText'] = community_df.groupby('DayIndex')['CommunityText'].apply(list)
total_df['MetricIndex'] = community_df.groupby('DayIndex')['MetricIndex'].apply(list)
데이터 라벨링
본 프로젝트에서 사용한 머신러닝 모델은 지도학습 모델이기에, 투자에 대한 신호를 시계열 데이터에 대응한 후 학습시키고자 하였다. 이를 통해 모델은 텍스트 데이터를 기반으로 적절한 투자 신호를 제공할 수 있다. 따라서 전처리 단계에서 적용한 시간 묶음당 매매를 하는 것이 적절한지에 대해 라벨링하였다.
이를 위하여 한국무위험지표금리(KOFR)를 이용하여 기간에 맞추어 계산 후 시세차익과 무위험수익률을 비교하여 주식의 매수/매도 추천을 하였다. 단기적인 상승세가 나타나면 2, 장기적인 상승세가 나타나면 1, 해당사항이 없을 경우 0으로 라벨링하였다. 사용한 코드는 다음과 같다.
data["Label"] = 0
for i in data.index:
d = i//7
if data.loc[i, "Close"] * (1+RFRD) <= data.loc[i+1, "Low"]: # 당일 종가와 내일 저가
data.loc[i, "Label"] = 2
elif data.loc[i, "Close"] * (1+RFRW) < mean[d+1]: # 당일 종가와 다음주 평균가
data.loc[i, "Label"] = 1
모델 설계
모델 구조 및 세부사항
머신러닝 모델에 대한 코드는 해당 링크에서 확인할 수 있다. 머신러닝
Dataset에 대한 코드는Data폴더에서, 모델에 대한 코드는Model폴더에서 확인할 수 있다. 모델의 학습과 테스트에 대한 코드는train_test.py파일에 작성되어 있다.
모델 구조는 다음과 같다.
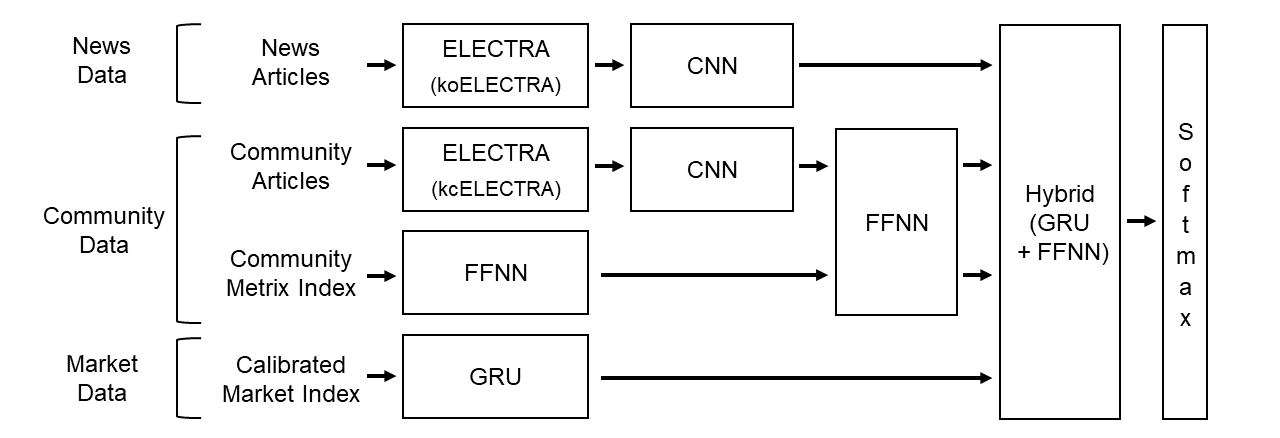
ELECTRA는 구글에서 발표한 pre-trained 트랜스포머 모델이다. 트랜스포머 모델은 인간의 집중력을 모방한 Multi-head Attention을 이용하여 자연어를 처리하는 모델로, 2017년 구글에서 발표된 논문인 'Attension is All You Need'에서 제시되었다. Word2Vec, Seq2Seq 등 기존의 모델보다 자연어 처리 성능이 뛰어나 오늘날 ChatGPT등 다양한 고수준 자연어 처리 분야에서 가장 많이 사용되는 모델이다. ELECTRA는 구글에서 발표된 모델로 적은 컴퓨팅 리소스로도 사용 목적에 맞게 모델을 수정하는 Fine-Tuning이 가능해 해당 모델을 채택하였다. koELECTRA, kcELECTRA는 ELECTRA를 한국어에 맞게 Fine-Tuning된 모델로, koELECTRA는 위키백과, 뉴스 기사등 문어체를 준수하고 상대적으로 복잡한 문장구조를 지닌 자연어 데이터(말뭉치, 코퍼스)에 Fine-Tuning되었기 때문에, koELECTRA를 각 신문사의 뉴스 기사를 분석하는데 사용했다. 반면 kcELECTRA는 네이버 뉴스 대댓글 등 일상적으로 사용하는 구어체와 문어체와 섞이고, 문법이 적절하게 준수되지 않는 등 일상적으로 생성된 데이터에 Fine-Tuning되었기 때문에 트위터와 종목 토론방을 분석하는 데 사용했다. 각 ELECTRA 모델로 코퍼스를 벡터로 임베딩했고 전체 데이터를 3차원 텐서로 재구성했다.
이렇게 텐서로 재구성된 코퍼스는 3D CNN(Convolution Neural Network)거쳐 분석된다. 초기 설계에서는 별도의 트랜스포머 모델을 적용하고자 했으나, 대량의 컴퓨터 처리 자원을 요구하는 트랜스포머의 특징으로 인해 도입하지 못했다. 대신 입력 데이터에서 특징을 추출하는 데 강점을 보이는 CNN을 도입하여 전반적인 문맥을 분석하도록 했다. CNN의 커널에는 Computer Vision에 사용되는 대칭형 커널이 아닌 비대칭형 커널을 사용했다. Computer Vision에서 CNN 커널이 이미지의 패턴을 찾는 것과 달리 자연어 처리의 CNN의 커널은 문맥을 파악하는 역할을 하기 때문에, 여러 임베딩 벡터들을 한번에 인식할 수 있도록 비대칭 커널을 설정하는 것이 일반적으로 좋은 성능을 내기 때문이다.
주식 가격은 시계열 데이터이므로, RNN(Recurent Neural Network)계열인 GRU(Gated Recurrent Unit)를 적용했다. 현재는 컴퓨터 자원의 제약과 시간적 제약으로 인해 데이터셋의 규모가 작으므로 과적합을 막기 위한 Regularization 전략으로 LSTM 대신 GRU를 도입했다. GRU는 LSTM보다 파라미터의 수가 작아 모델의 크기가 작으면서도 일반적으로 LSTM과 비슷한 수준의 성능을 보이기 때문에 주어진 상황에 적절하다고 판단했다.
각 신경망 서브 모델의 출력은 한데로 모아진 후 Flatten하여 GRU와 FFNN(Feed Forward Neural Network)이 혼합된 신경망으로 보내진다. 이 신경망은 각 입력 피처를 모두 받아들여 종합적인 의사 결정을 하는 역할을 한다. 일부 데이터는 시계열 데이터이므로 순환신경망인 GRU에 대입된 후 FFNN에, CNN의 출력들은 바로 FFNN에 대입된다. FFNN은 가장 기본적인 신경망 기본 요소이면서 이전 입력 피처를 처리하는 데 자주 사용되므로 FFNN을 선택했다. 기본적으로 적용된 FFNN은 아무런 기법이 적용되어 있지 않지만, 필요에 따라 $L_1,\ L_2$ Regularization, Dropout과 같은 Regularization 기법이나 Batch Normalization, Residual Connection과 같은 기법을 적용할 수 있도록 했다.
최종적으로는 Softmax 함수에 값을 대입하여 각 가능성에 대한 확률을 산출한다. Softmax 함수는 다음과 같이 정의된다. \(\begin{array}{l} \text{For Given Vector\ } z^{[L]} = \begin{bmatrix} z_0\\ z_1\\ z_2\\ z_3 \end{bmatrix},\ a^{[L]} = softmax\left(z^{L} \right) = \frac{e^{z^{[L]}}}{\sum\limits_{i=0}^{4}z^{[L]}_i} = \begin{bmatrix} \frac{e^{z_0}}{\sum\limits_{i=0}^{4}e^{z_i}}\\ \frac{e^{z_1}}{\sum\limits_{i=0}^{4}e^{z_i}}\\ \frac{e^{z_2}}{\sum\limits_{i=0}^{4}e^{z_i}}\\ \frac{e^{z_3}}{\sum\limits_{i=0}^{4}e^{z_i}} \end{bmatrix} \end{array}\) 주어진 식에서 알 수 있듯이, Sotfmax 함수는 입력 피처를 확률로 변경시켜 출력한다. Softmax 함수가 적용된 Softmax 층은 이전 FFNN 층에서 분석된 데이터를 입력 피처로 받아들여 확률을 출력한다. 해당 확률만으로도 의사결정이 가능하다. 또, Softmax 층을 제거하고 새로운 신경망 모듈을 올려서 필요한 목적에 맞게 신경망을 재사용하는 전이학습을 수행할 수도 있다. 가령 Softmax 층을 제거하고 적절하게 설계된 신경망 모듈을 올려서 스스로 금융 상품 가격과 그에 대한 인식을 판단한 후 금융 상품 거래를 수행하는 트레이딩 봇을 개발할 수 있다. 그 외에도 보다 복잡한 의사결정을 수행하는 새로운 신경망 모델을 개발할 수도 있다.
구현
먼저 prepare-dataset.ipynb로 준비된 pickle 데이터파일을 train_test.py 코드가 데이터셋으로 받을 수 있도록 텐서로 변환해준다. 훈련을 진행할 때에는 메모리상의 문제로 한번에 모든 데이터를 변환하지않고 수번에 걸쳐 변환하였다.
학습이 진행되면 변환된 텐서 데이터셋을 받아오고 설정해둔 하이퍼파라미터 값인 epoch, train_size, batch_size에 따라 학습이 진행된다. 이 파라미터 값으로는 학습이 진행되는 환경과 준비된 데이터의 크기에 따라 조정하면 된다. 데이터 탐색에서 결정한 사항에 따라 뉴스 기사 데이터의 부분은 구현하지 않기로 결정했다. 따라서 입력 피처는 종목 토론방에 대한 텍스트 데이터와 이에 대한 반응 지표, 그리고 금융 상품 가격으로 결정했다.
데이터셋의 준비 및 입력이 끝나면 이 데이터셋을 기반으로 MainModel.py가 실행된다. 신경망 모델의 연산은 순방향 전파(Forward Prop.)와 역방향 전파(Back Prop.)으로 나뉜다.
먼저 순방향 전파는 CNN, GRU, FFNN 세 신경망 기본 구성 요소들의 연산으로 구성된다. 이 CNN은 입력된 뉴스 기사와 커뮤니티 데이터를 ELECTRA로 처리한 텐서 데이터들을 처리한다. 이 부분에서 설정해야할 하이퍼 파라미터들은 in_channels, out_channels, kernal_size, stride, padding이 있다. (out_channels)/(in_channels)의 값이 커널의 갯수가 된다. channel의 수와 크기는 반비례한다. kernal은 데이터셋에 대해 적용되는 필터로, 이 필터 파라미터가 학습의 대상이 된다. 이 학습의 경우, 이미지가 아닌 텍스트파일을 학습하는 것이므로 문맥파악에 용이하도록 높이의 값(더 많은 행을 포함)이 높은 비대칭 필터로 설정하였다. stride는 kernal이 이동할 간격을 말한다. 출력 데이터의 크기를 조절하기 위해 사용되는데 1처럼 작은 값이 잘 작동한다. padding은 입력데이터 주변을 특정값으로 채워놓는 것을 말한다. 이는 출력 데이터의 크기(Spatial)을 조정하며 데이터가 CNN의 층을 지날 때마다 가장자리의 정보가 사라지기 때문에 사용한다. 이 때 pooling은 최대값을 찾아 채워넣는 Max-Pooling을 사용한다.
한편 community_metric_ffn 는 community Metrix index 데이터를 처리한다. 이 FFNN에서 설정할 하이퍼 파라미터에는 in_feature와 out_feature가 있는데 in_feature는 입력된 데이터 텐서의 크기에 맞게 설정하고 out_feature는 return되는 출력값을 설정하면 된다.
다음으로는 community_ffn이 실행된다. 이 FFNN은 community articles를 CNN처리한 값과 위의 FFNN에서 처리한 값을 입력으로 받아 처리하는 모델이다. 이 모델도 마찬가지로 in_feature와 out_feature를 설정하면 된다.
GRU모델도 실행을 하는데 이 모델은 주가 데이터인 Calibrated Market Index를 입력받아 작동한다. 이 모델은 input_size를 제외한 파라미터 값들만 조정하면 된다.
Flatten함수는 텐서의 차원을 1차원으로 평면화한다. 이전 CNN, GRU, FFNN의 출력 결과를 모두 모아 1차원 벡터로 구성하는 역할을 한다. 여기까지 실행이 끝나면 각 데이터에 대해 처리되어 출력된 값들이 total_ffn에 입력되어 실행된다. FFNN으로 처리가 진행되는데 in_features와 out_features의 값들이 다른 층의 출력에 맞게 조정되어야 한다. 따라서 이전 층의 출력 벡터의 크기를 구할 필요가 있다. CNN에서의 출력 크기는 텐서의 각 출력 차원에 대해,
위의 식을 적용하면 된다. 이 출력 크기 모두를 곱하면 최종적인 CNN층의 출력크기를 구할 수 있다. 다른 신경망 구성요소의 경우는 직접 설정할 수 있으므로 쉽게 구할 수 있다. total_ffn의 실행이 끝나면 마지막으로 softmax가 실행된다. softmax의 in_features와 out_features의 값은 total_ffn의 출력에 따라 설정하면 된다.
이렇게 얻은 순방향 전파 결과와 실제 라벨링 된 값을 비교하여 오차를 구하고, 오차를 바탕으로 파라미터 값을 갱신하여 모델을 최적화하는 역방향 전파를 수행한다. 오차에 대한 모델의 최적화에는 Adam 최적화 알고리즘을 사용했다. Adam은 Momentom 과 RMSProp 알고리즘을 합친 알고리즘으로 일반적인 대부분의 경우에서 좋은 성능을 낸다. 전체 데이터셋에 대해 epoch의 값만큼 반복 학습이 진행된다.
모델의 파라미터는 model-dir 폴더에 저장된다.
추후 발전 방향
기술적 분석 모델 설계
정량적 지표만을 사용한 기술적 분석 모델을 설계한다. 추세지표, 모멘텀지표, 변동성지표, 시장강도지표 등의 자료만을 이용하여 백테스트를 통해 모델을 구성한다. 이후 귀사의 비정형 데이터 처리 모델과 비교·대조하여 장점만을 취하여 발전시킨다. 또한 비교 결과 귀사의 모델만이 가진 강점을 판매전략에 활용할 것이다.
추가 데이터 수집, 탐색 및 전처리
추가적인 데이터 수집을 수행한다. 일반적으로 데이터 증가는 모델의 성능을 개선시키고 과적합을 억제한다. 또 더 규모가 큰 모델을 적용할 수 있게 한다. 데이터 탐색을 진행하여 데이터의 특징을 살펴본다. 인공지능이 학습할 수 있는 데이터를 늘려서 성능의 고도화를 꾀한다.
모델 학습 및 개선
컴퓨터 처리 자원을 확장하여 자연어 처리 부분에서 트랜스포머 모델을 적용해 성능을 더욱 끌어 올린다. 많은 경우에서 트랜스포머 모델은 CNN에 비해 매우 높은 성능을 보여주므로 모델의 성능을 더 높일 수 있을 것으로 기대된다. 데이터 양이 커짐에 따라 요구되는 컴퓨팅 자원의 양도 늘어나기에 최적화 문제 또한 따라가야 할 문제라고 생각한다. 주가의 가까운 미래에서의 경향성을 예측하므로, 빠른 처리가 이루어져야 추가적인 시세차익을 기대할 수 있다. 따라서 최적화나, 컴퓨팅 자원을 갖지 못한 고객에게 예측 서비스를 제공하는 사업 모델 또한 언급되었다. 또한 추가적인 하이퍼파라미터 탐색을 통해 모델 최적화와 성능 향상을 도모한다. 종목별로 주주의 커뮤니티 참여도나, 주가 변동성이 차이가 있으므로, 이에 따른 미세 조정 또한 모델을 발전시켜나가야 할 방향성이라고 볼 수 있을 것이다.
데이터 파이프라인 구축
보유 서버를 확충하고 인프라를 설정하여 데이터 파이프라인을 구축한다. 데이터 파이프라인을 통해 실시간으로 생성되는 텍스트 데이터와 금융상품 데이터를 수집하고 데이터셋에 추가하여 모델의 성능 향상을 기대할 수 있다. 특히 데이터가 추가됨에 따라 과적합에 대한 문제가 줄어들어 모델의 복잡도를 높일 수 있으므로, 모델의 복잡도를 높이는 방향으로 설계를 변경하고 이에 대한 추가적인 성능 향상을 기대할 수 있다. 또한 추가적인 텍스트 데이터 도메인을 확장하고 데이터를 수집하여 다각적인 분석을 수행한다.
상관관계를 가지고 있는 다른 금융상품 데이터를 탐색하고 이를 모델에 적용해 추가적인 성능향상을 도모한다.
모델 기반 트레이딩 봇 개발
개발된 자연어 처리 모델을 기반으로 트레이딩 봇을 개발한다. 개발과 모델 성능 개선 및 최적화가 완료된 모델에서 Softmax 계층을 제거한 후 그 위에 다른 신경망 모델을 올려 전이학습 기반 트레이딩 봇을 개발한다. 트레이딩 봇(에이전트)의 훈련은 강화학습으로 진행한다. 강화학습은 에이전트와 환경의 상호작용을 통해 에이전트가 더 많은 보상을 얻는 방향으로 스스로 학습하는 학습 방법이다. 매우 거대한 규모의 금융 거래 시장 특성 상 트레이딩 봇의 결정이 금융 시장에 미치는 영향은 매우 작을 것이므로, 트레이딩 봇의 학습 환경은 기존의 금융상품 변동 추이 데이터를 활용할 수 있을 것이다. 하지만 강화학습을 위해서는 많은 데이터와 설계 자원, 컴퓨터 처리 자원이 필요하다.